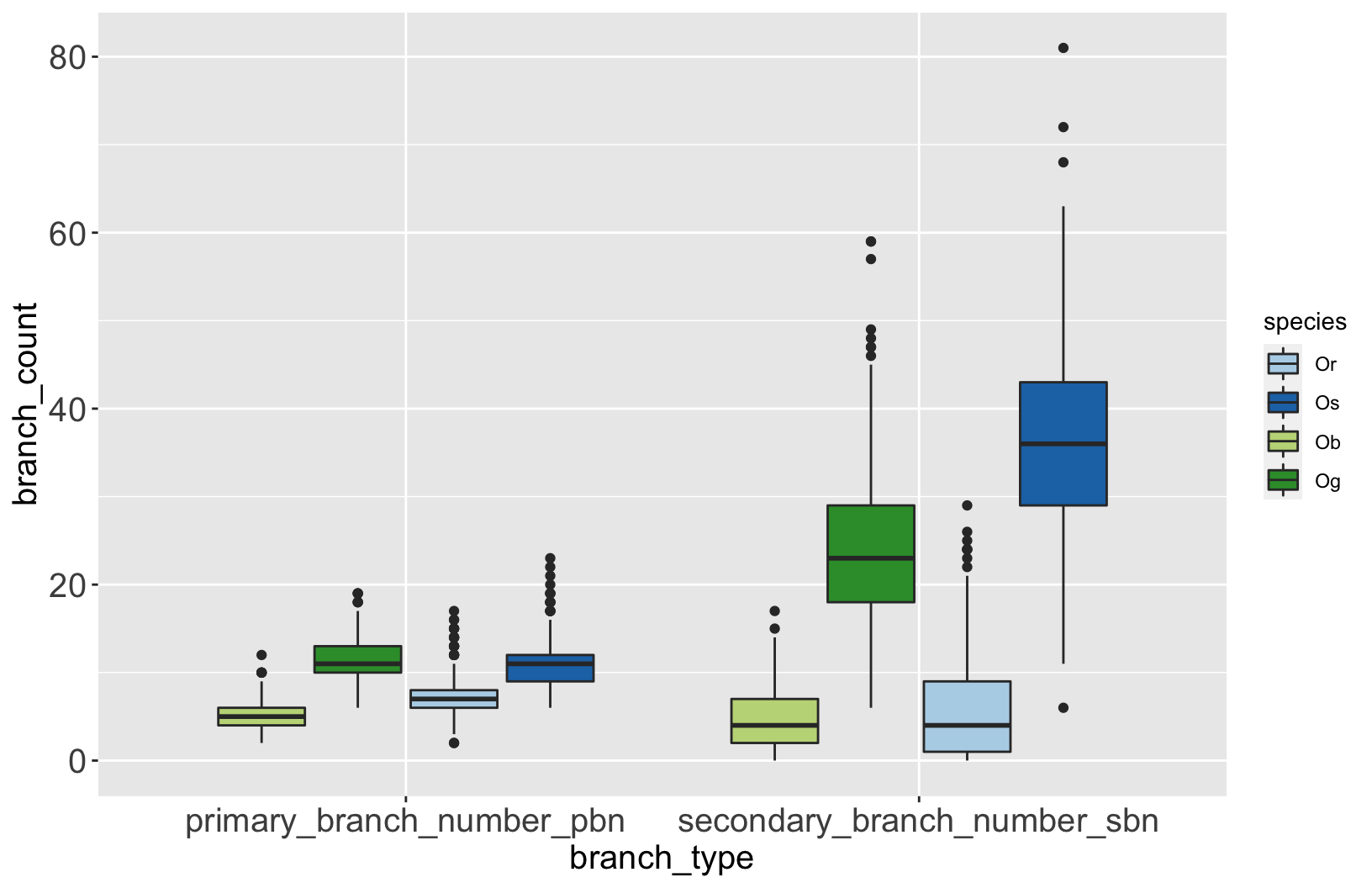
| species_id | species | continent | status |
|---|---|---|---|
| Ob | Oryza barthii | African | Wild |
| Og | Oryza glaberrima | African | Cultivated |
| Or | Oryza rufipogon | Asian | Wild |
| Os | Oryza sativa | Asian | Cultivated |
Explorative Data Analysis
Tidyverse - Part 5
The steps of EDA
We have covered almost all steps of what is called Explorative Data Analysis (EDA).
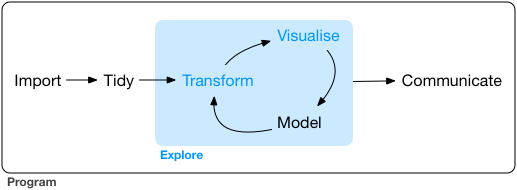
Image Source: R4DS
Transcriptome and Phenotype of multiple Rice species
A set of AP2-like genes is associated with inflorescence branching and architecture in domesticated rice.

- Paper
- DOWNLOAD SUPPLEMENTARY TABLE S3 - 96Kb !It’s a CSV file!
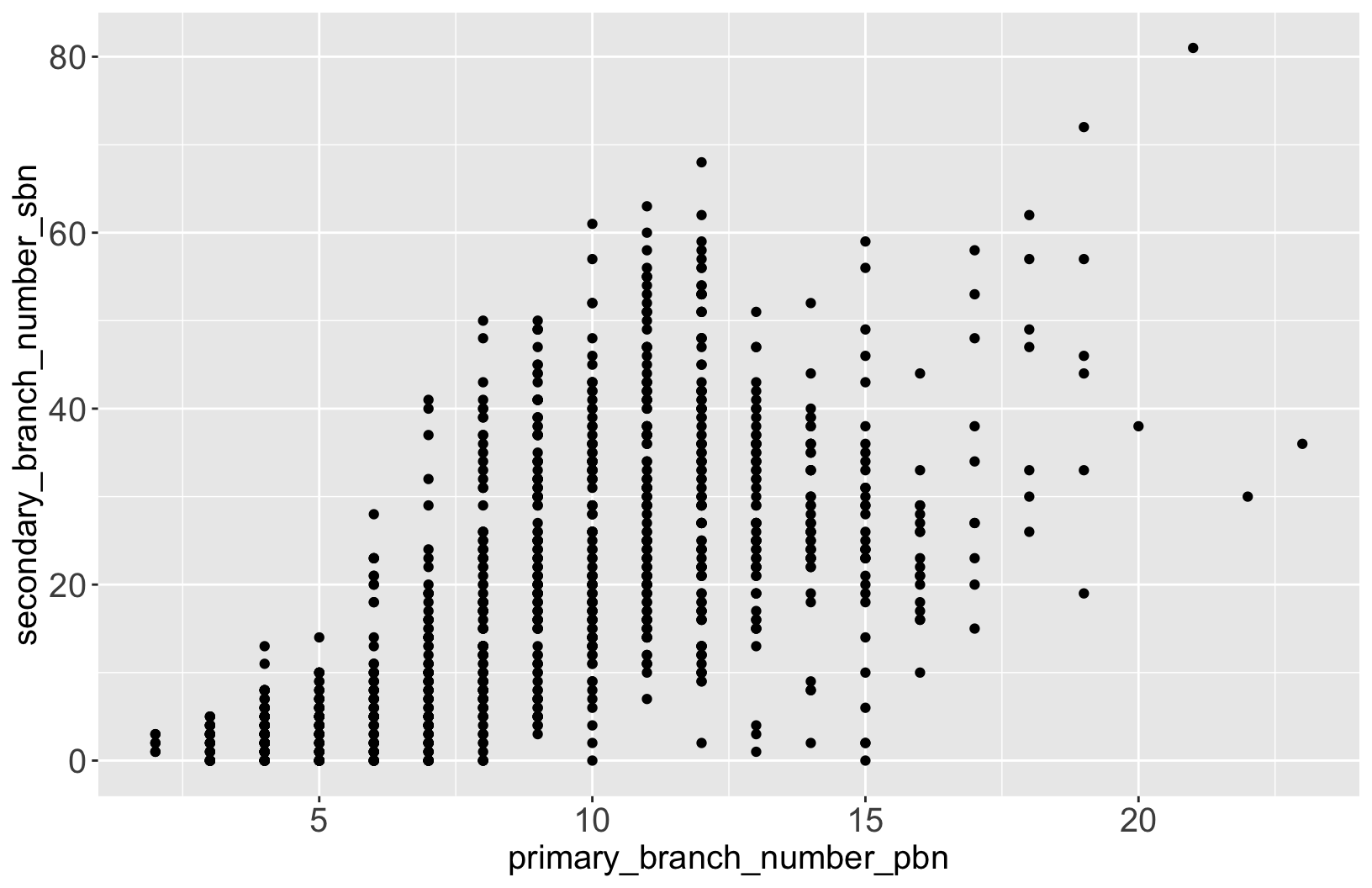
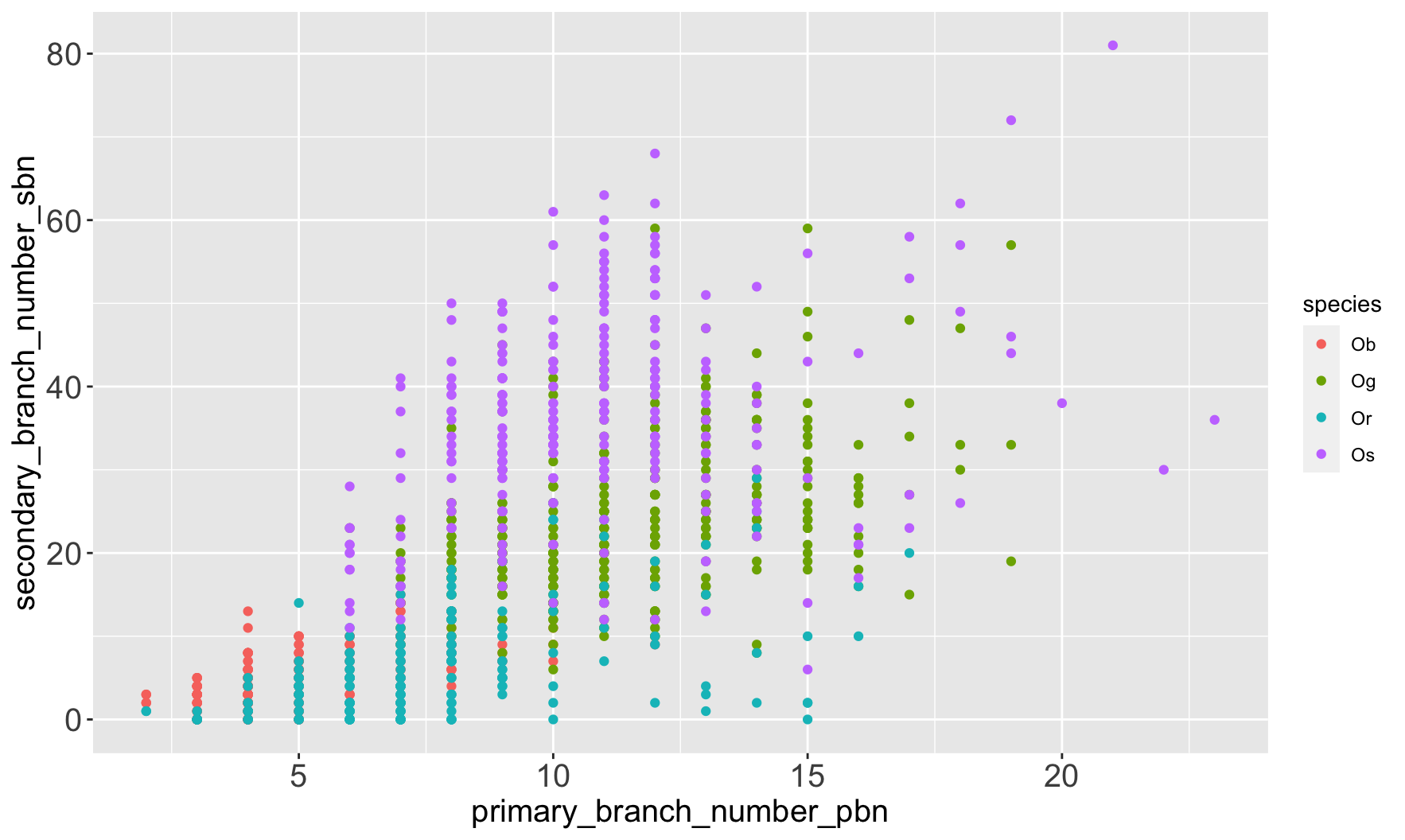
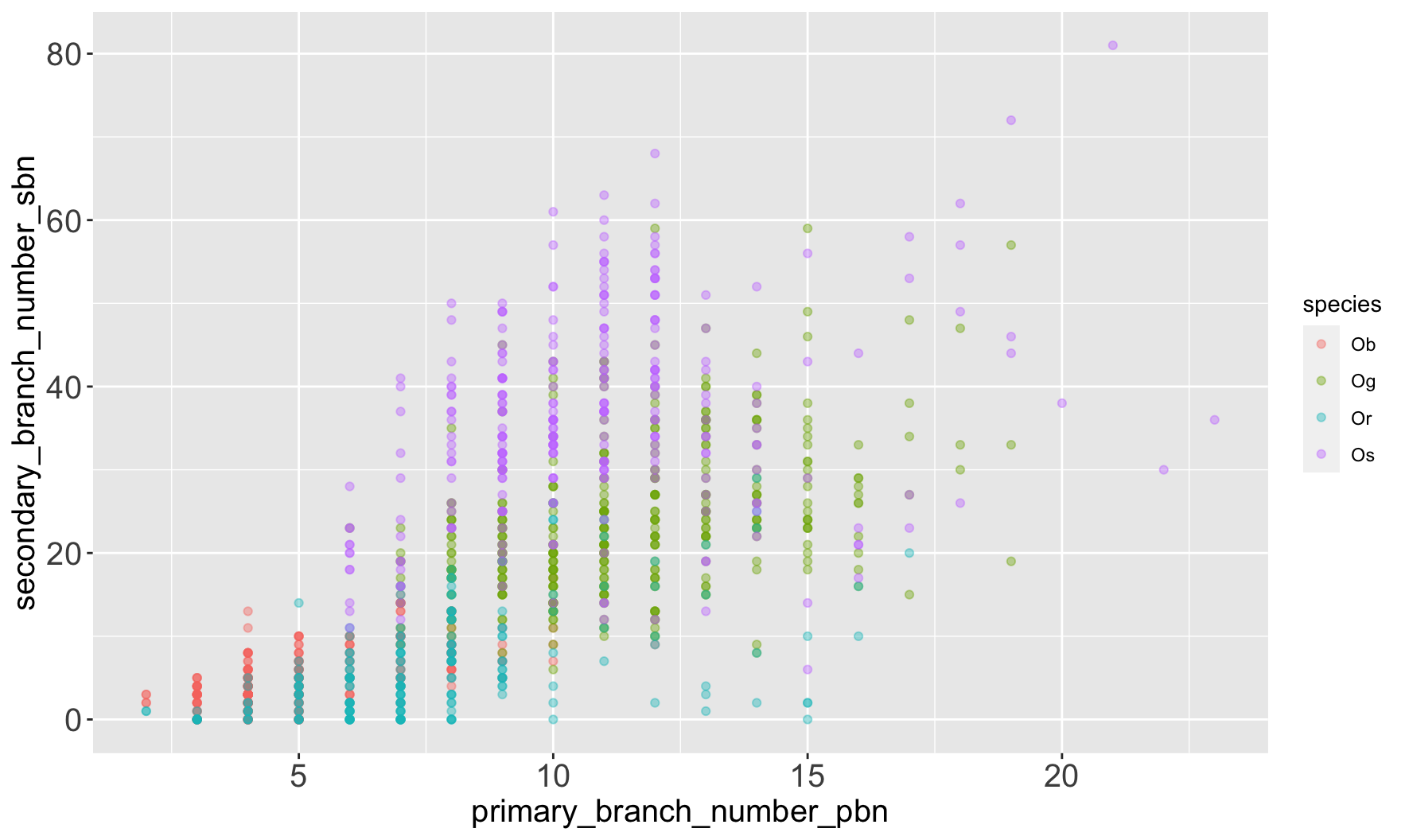
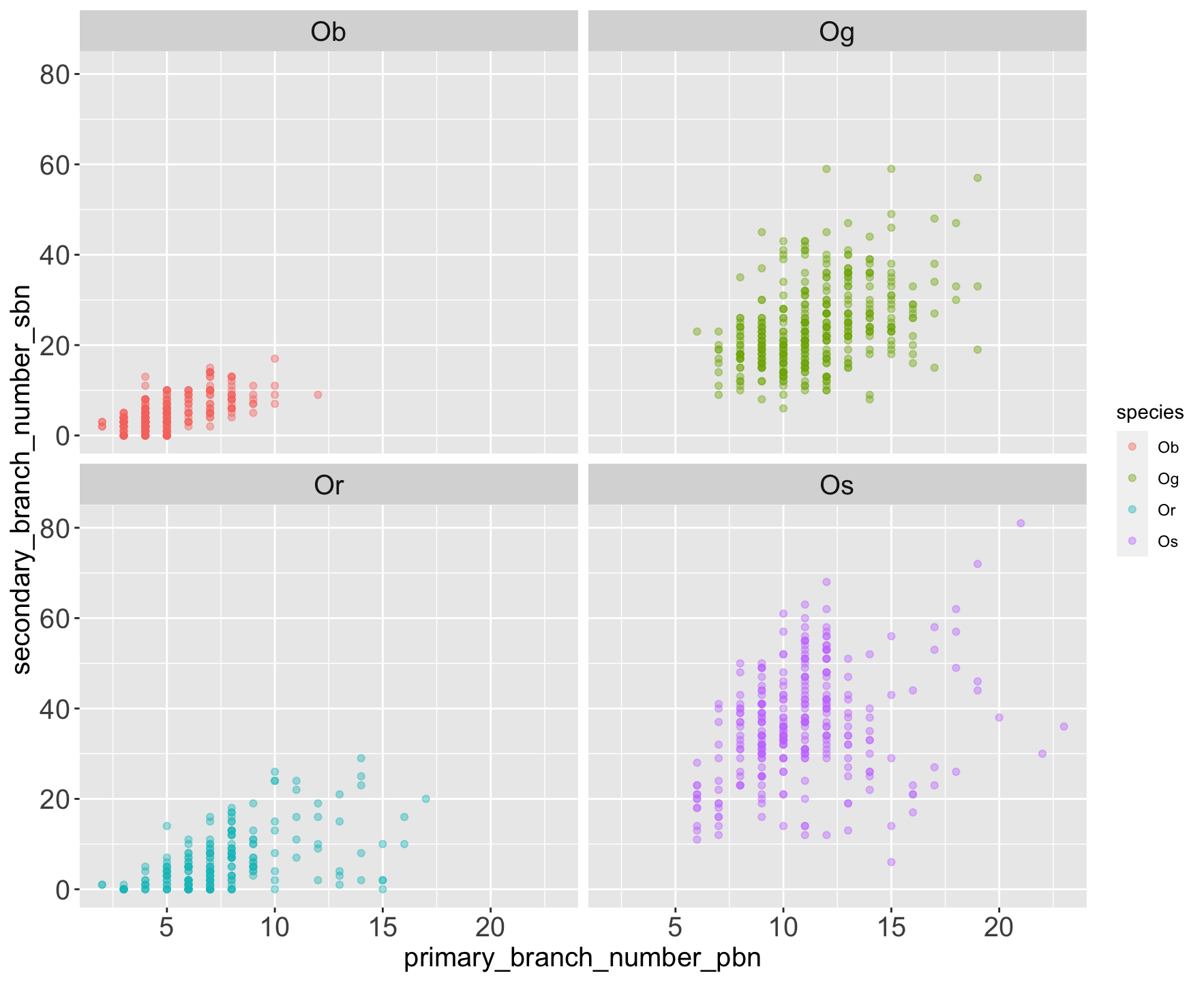
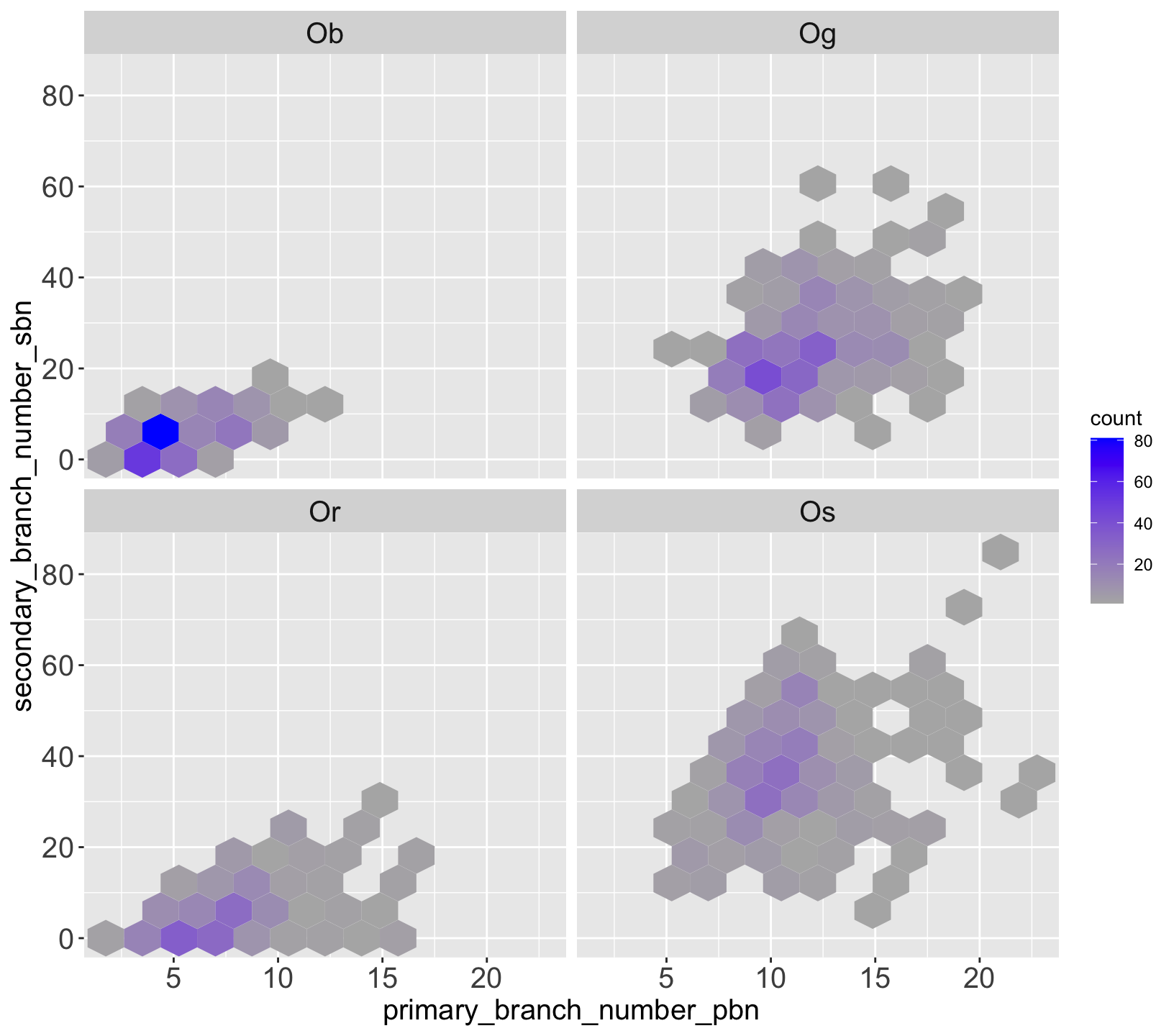
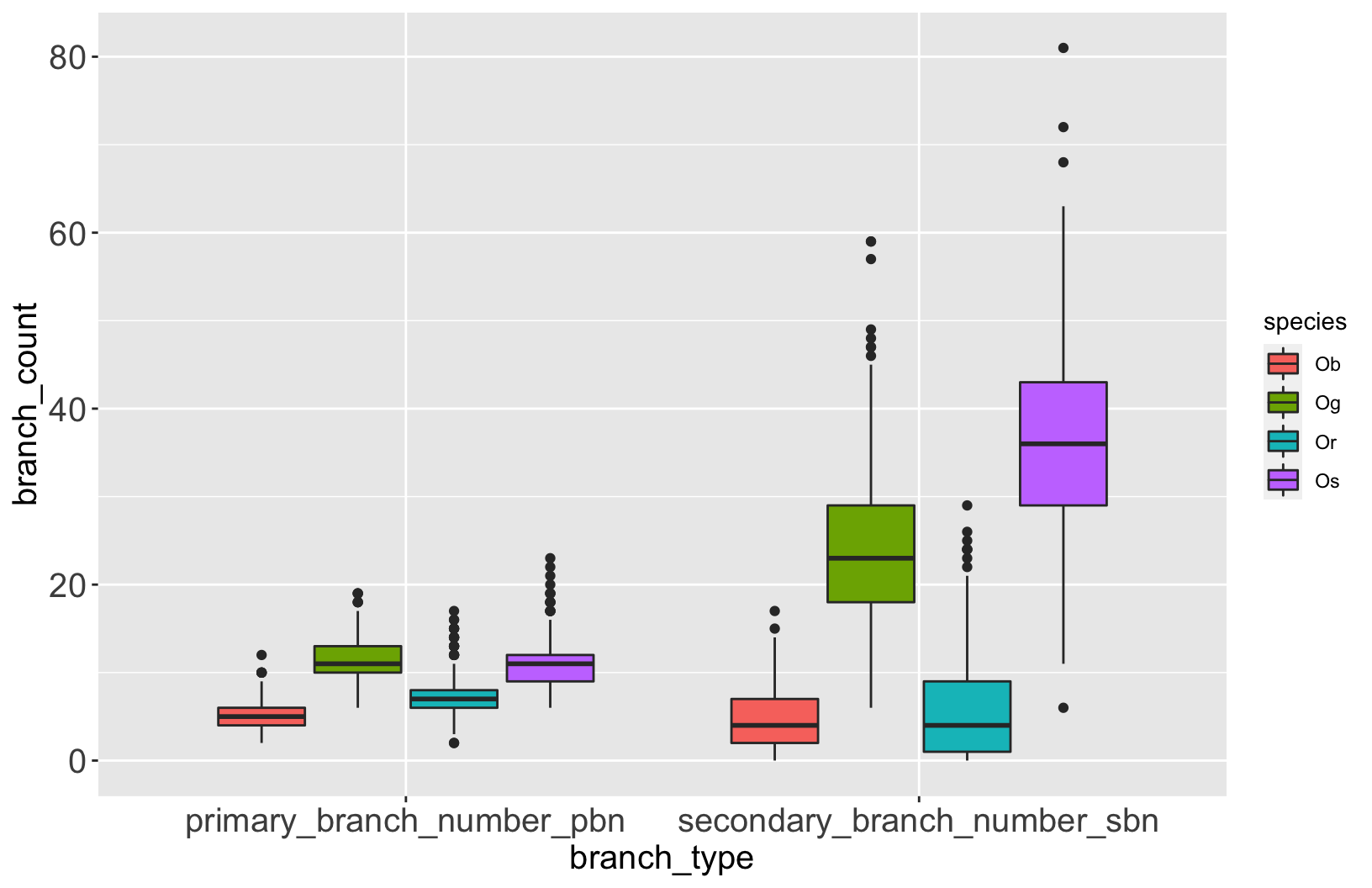
# define colors
rice_colors <-
c(Or = '#b5d4e9',
Os = '#1f74b4',
Ob = '#c0d787',
Og = '#349a37')
# plot
rice %>%
select(species,
primary_branch_number_pbn,
secondary_branch_number_sbn) %>%
pivot_longer(-species,
names_to = 'branch_type',
values_to = 'branch_count') %>%
ggplot(aes(x = branch_type,
y = branch_count,
fill = species)) +
geom_boxplot() +
scale_fill_manual(values = rice_colors)