Robust Summary Statistics
Mean and Standard Deviation
- Mean
\(mean(x) = \frac{1}{n} \sum_{i=i}^{n} x_{i}\)
- Standatrd Deviation
\(SD = \sqrt{\frac{1}{N-1} \sum_{i=1}^N \left(x_i - \bar{x}\right)^2}\)
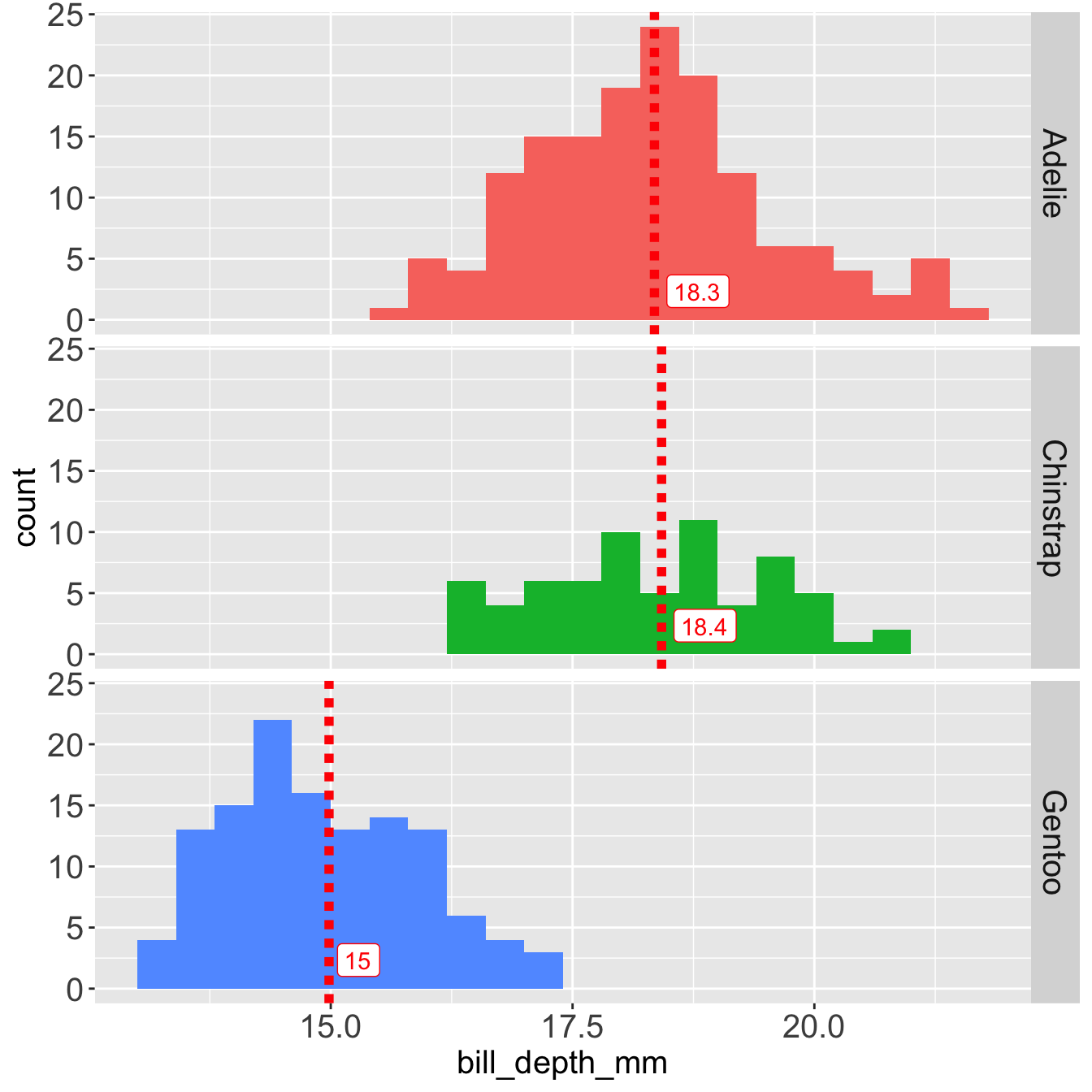
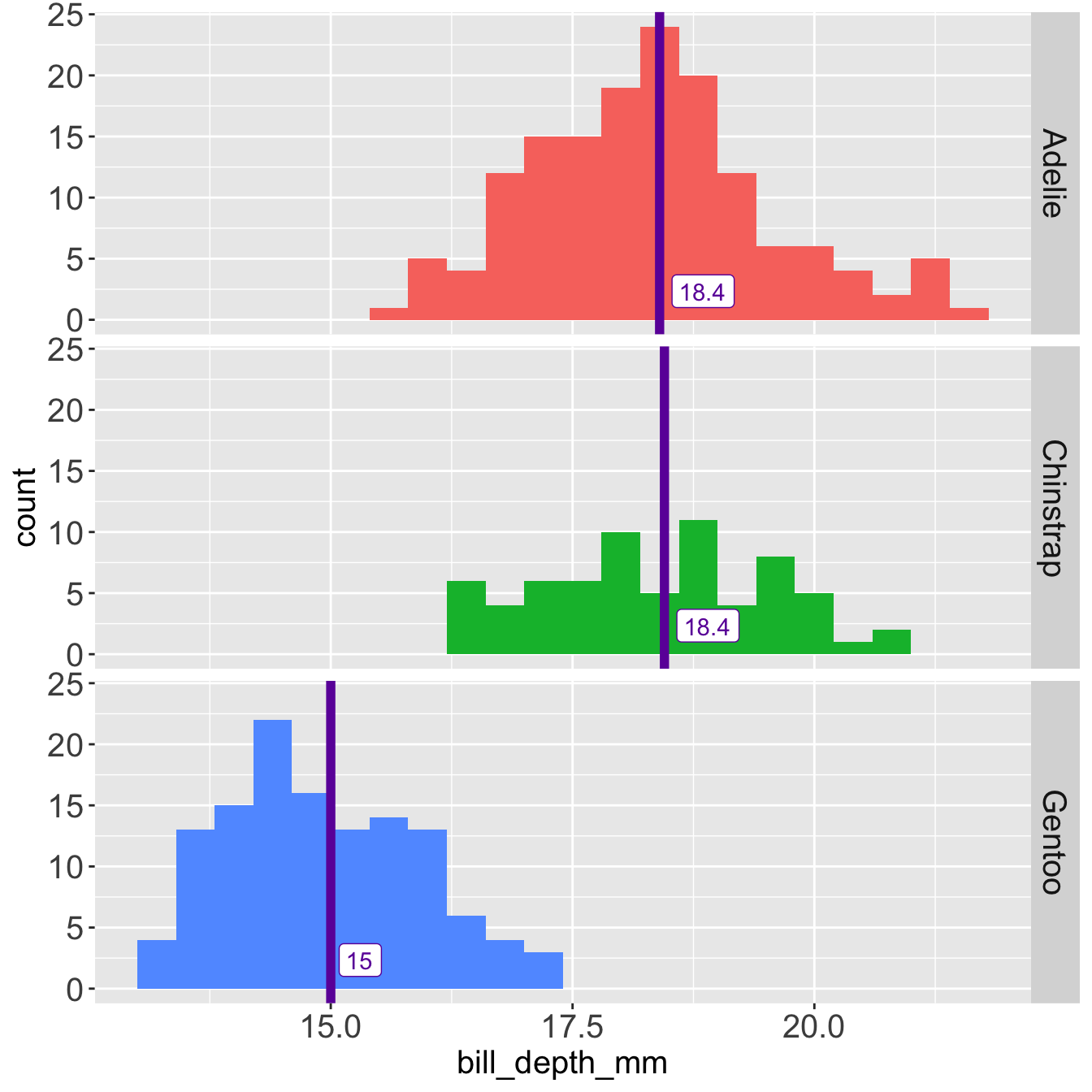
Mean and SD with an outlier at 215 mm
I’ve added an outlier to the Adelie species, let’s see what happens graphically
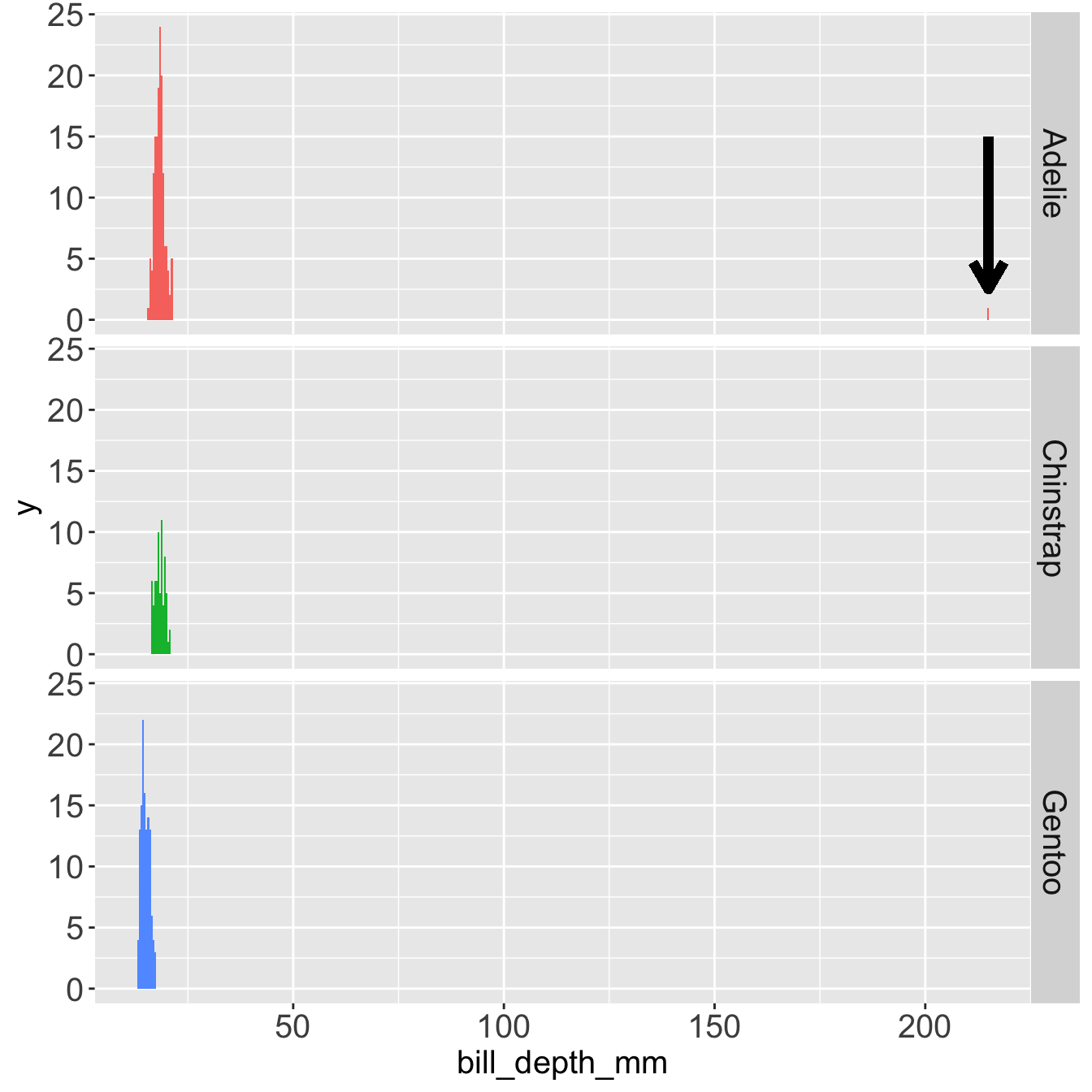
In the next plots I will not represent the outlier graphically because it stretches the x axis too much.
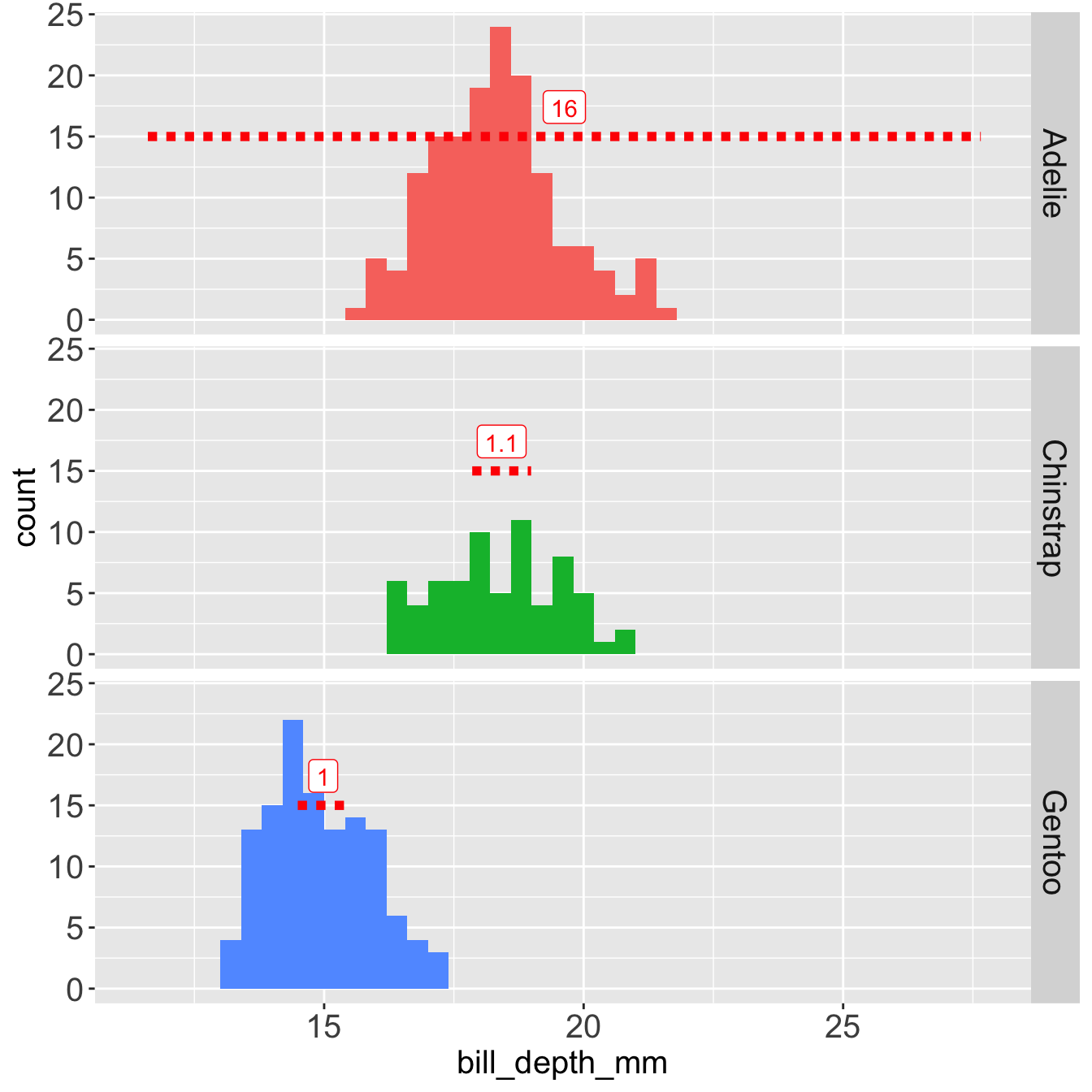
Mean and SD are heavily influenced by the outlier.
The mean of Adelie is influenced by the outlier at 215 mm
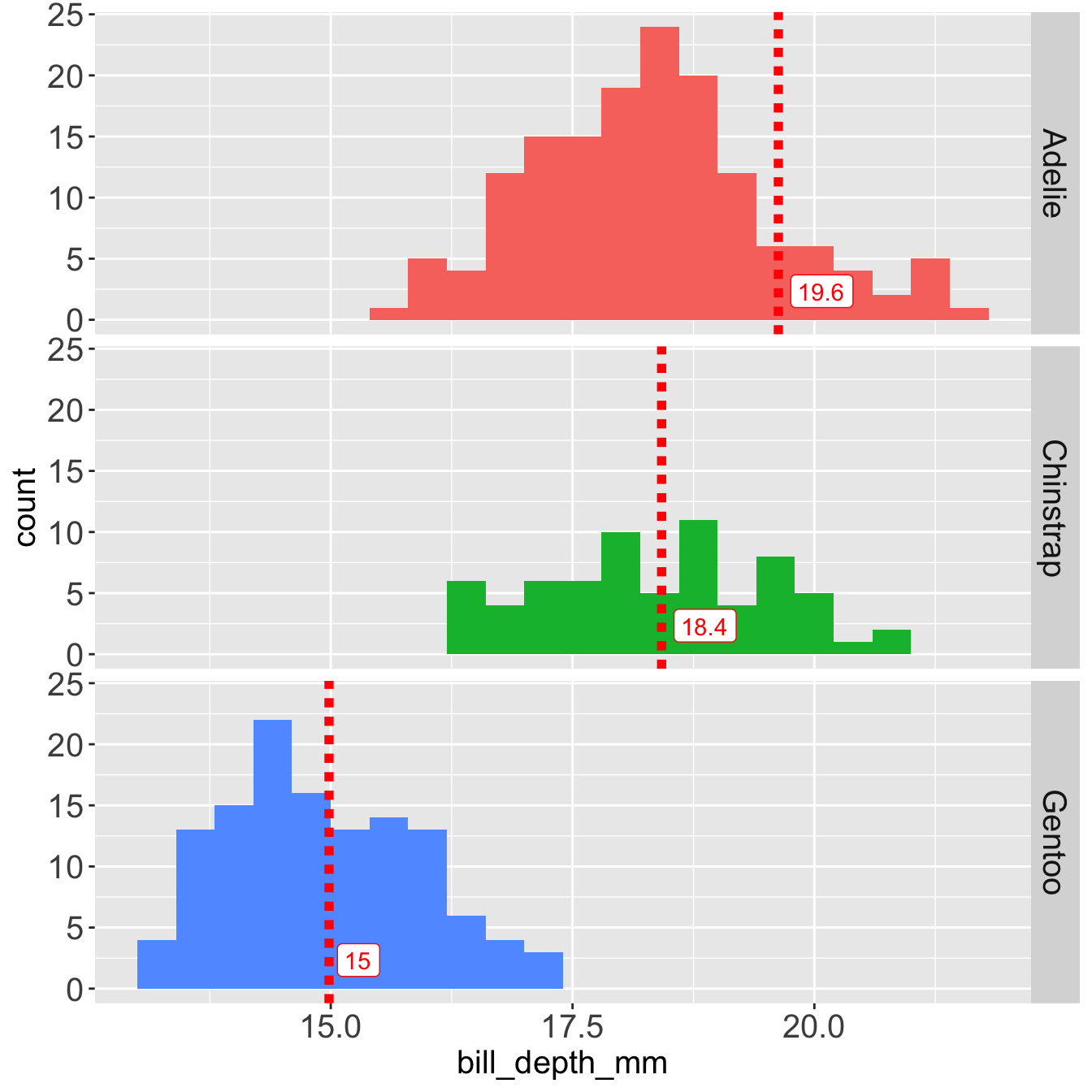
The SD of Adelie is influenced by the outlier 215 mm
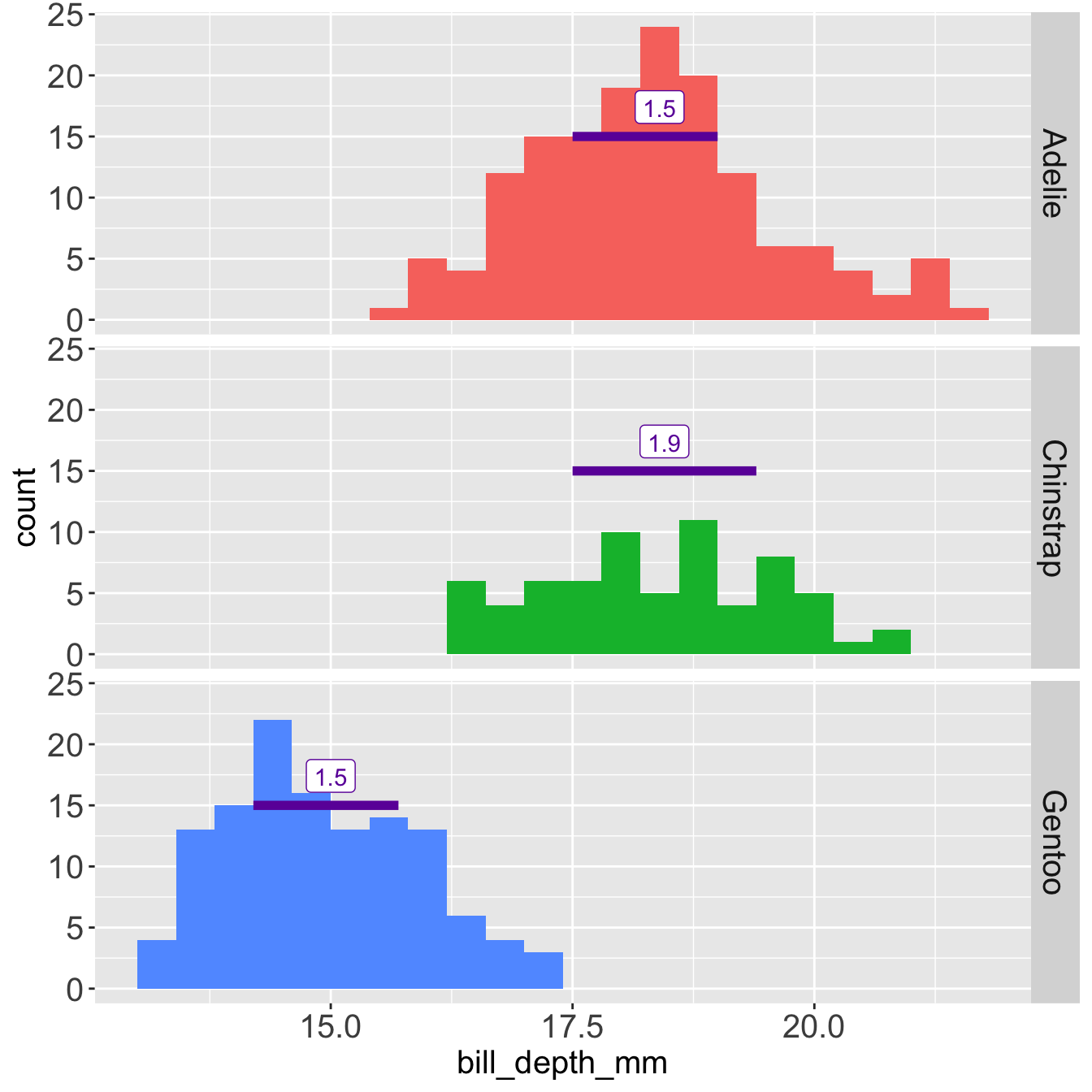
Median and IQR without outlier
- Median
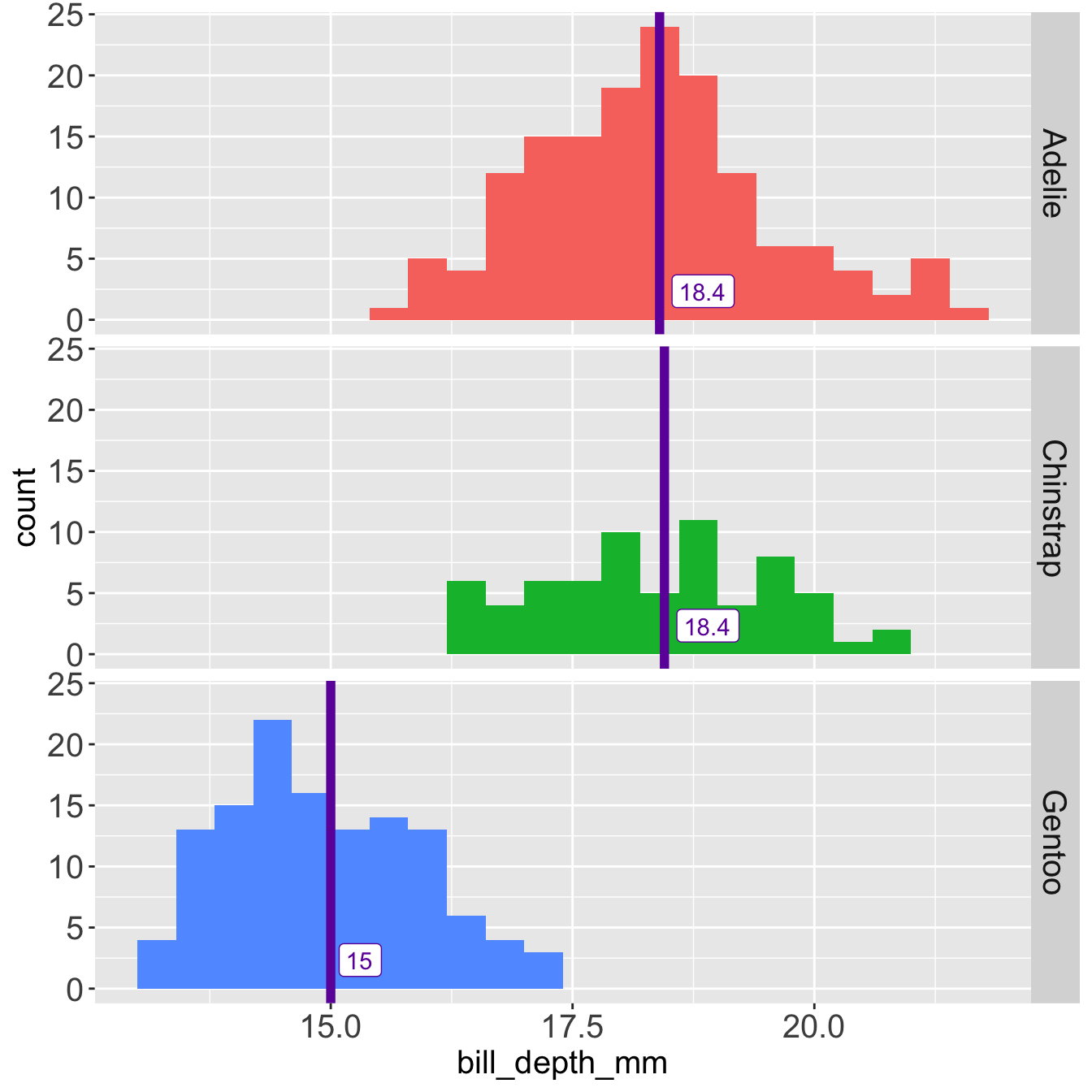
- IQR
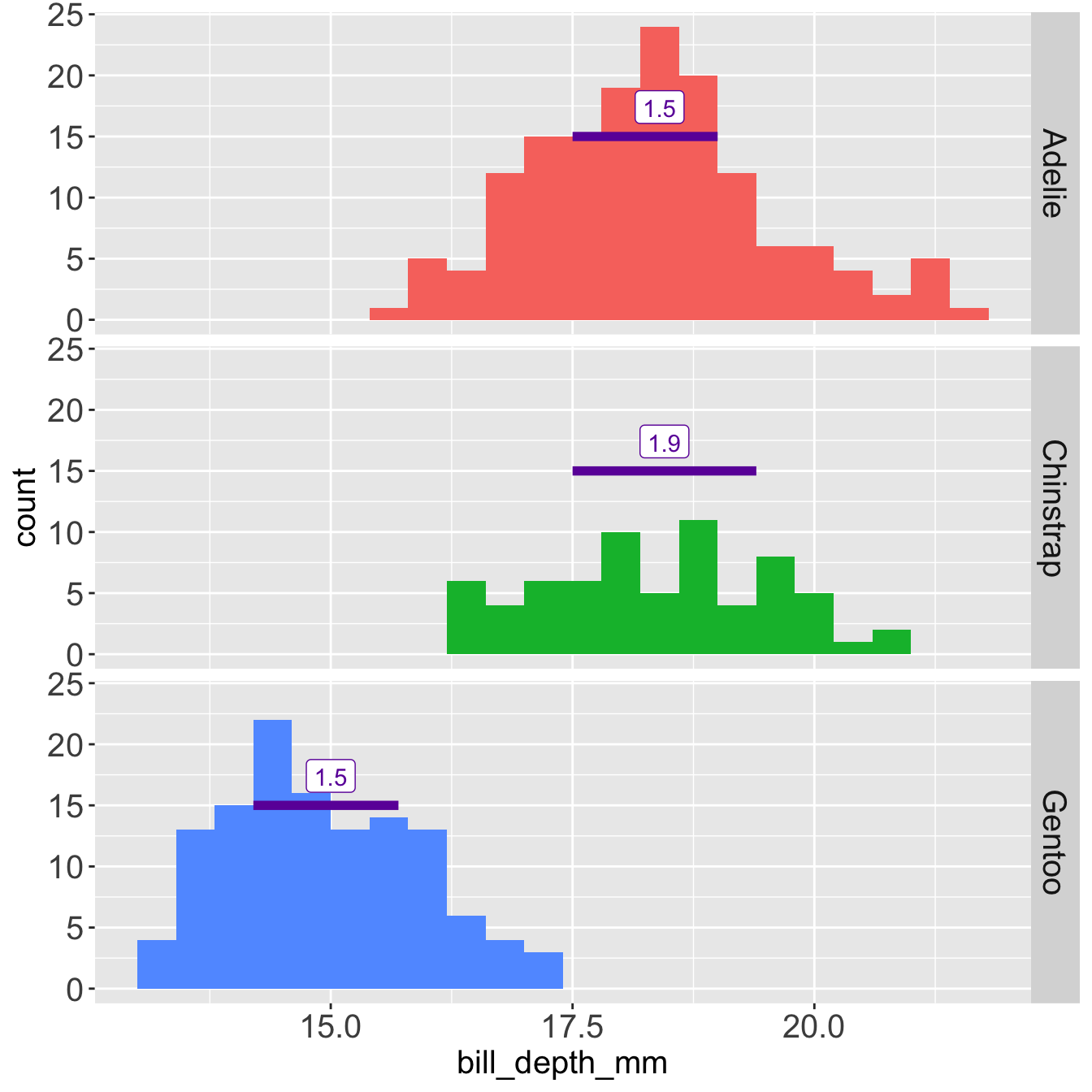
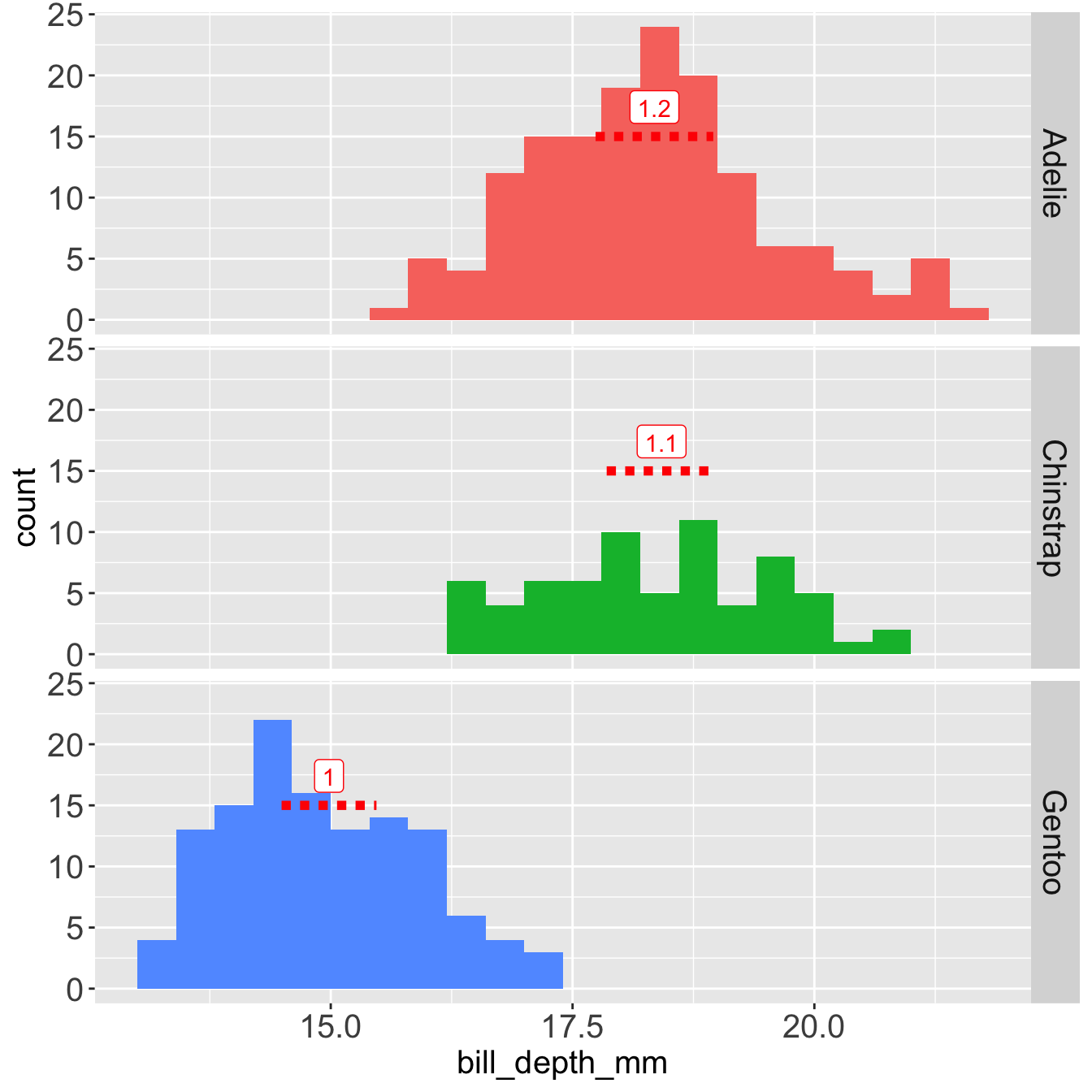
Median and IQR with an outlier at 215 mm
The median is not influenced by the outlier at 215 mm
The median is not influenced by the outlier at 215 mm